Прогноз данных в системе мониторинга
ЛОГИН Элина Валерьевна,
Петербургский государственный университет путей сообщения Императора Александра I, кафедра «Электрическая связь», доцент, канд. техн, наук, Санкт-Петербург, Россия
Ключевые слова: Data Science, прогнозирование, интеллектуальный анализ данных, телекоммуникационная сеть связи, регрессионный анализ
Аннотация. Контроль и оценка состояния оборудования в системе мониторинга производится посредством программных модулей. Основная их задача - сбор и частичная обработка данных, которые в разной степени дают оценку функционирования системы управления технологическим процессом. Осуществляемая модернизация системы мониторинга требует реструктуризации процессов сбора данных и развития модулей для их обработки с использованием сложных вычислений. Наравне с изменяющейся технической сложностью объектов управления усовершенствуются и подсистемы ЕСМА. В статье предложен вариант расширения функционала системы управления, который позволит в разрезе частично интеллектуальной обработки больших данных и предиктивной аналитики оперативно управлять состоянием устройств и независимо от степени сложности объекта адаптировать процессы управления в соответствии с современными телекоммуникационными технологиями.
ЦИФРОВАЯ ТРАНСФОРМАЦИЯ ОАО «РЖД»
■ Роль инноваций на железных дорогах в последние годы сильно возросла [1]. Наиболее перспективными направлениями цифровизации сегодня являются: безбумажный документооборот, гибкая аналитика, беспилотное движение, квантовые коммуникации, системы жизненного цикла объектов инфраструктуры (цифровые двойники, управление рисками) и система поддержки принятия решения (ИИ, цифровые модели, прогнозная аналитика).
Положительный эффект в этих направлениях возможен при планомерном развитии и модернизации информационно-коммуникационной инфраструктуры. Так, внедренная высокоскоростная сеть передачи данных представляет собой часть такой модернизации и служит основополагающей предпосылкой для создания модуля прогноза данных о состоянии объектов телекоммуникаций в системе мониторинга и администрирования. Этот модуль позволит сформировать интеллектуальный аспект в обработке данных путем
ее усовершенствования от классических процессов мониторинга и диагностики до «мягких» процессов управления и прогноза состояний.
При этом особое внимание уделено области, связанной с интеллектуальной обработкой данных, что обусловлено прикладным характером данного метода во всех направлениях цифровизации в перспективных инновациях.
ЭТАПЫ ПРОГНОЗА ДАННЫХ
■ Действующий программный алгоритм сбора данных в ЕСМА (были рассмотрены диагностические модули и TRS) является простым и прозрачным с точки зрения подготовки и актуализации процессов прогноза (интеллектуального анализа данных). В ближайшей перспективе планируется переход на новую систему управления технологическими сетями связи (ОУТ СО), в которой уже развернуты модули «Управление инцидентами и оперативный режим», «Коммутация данных» [2], а также другие модули, функционал которых уже стал неотъемлемой
частью оперативного процесса в мониторинге и администрировании технологических сетей связи. Возможное направление развития еще не запущенной системы ОУТ СС заключается в подготовке архитектуры хранения данных под новые процессы, появление которых в рамках модернизации и развития расширят возможности системы.
В первую очередь речь идет о реструктуризации источников данных и их адаптации под конфигурацию Big Data [3, 4], благодаря чему упрощается маршрут потоков данных. Также возможно применение облачных систем хранения данных для работы центров обработки данных и другие предложения по оптимизации технологических процессов их анализа.
Процесс обработки данных представляет собой последовательное выполнение операций с информацией в заданном временном промежутке. Преимуществами обработки данных в современных телекоммуникационных системах являются: увеличение скорости обработки; автоматизация процессов с большими данными; уменьшение количества ошибок, вызванных человеческим фактором.
Понятие «системы управления» неразрывно связано с технологией Big Data. Анализ большого объема информации в режиме реального времени дает возможность принимать обоснованные управленческие решения с высокой точностью и эффективностью [5]. Оценка этих показателей может быть выполнена внутри системы управления отдельными моделями (которые могут работать в режиме сбора статистики и в оперативном режиме) [6-8].
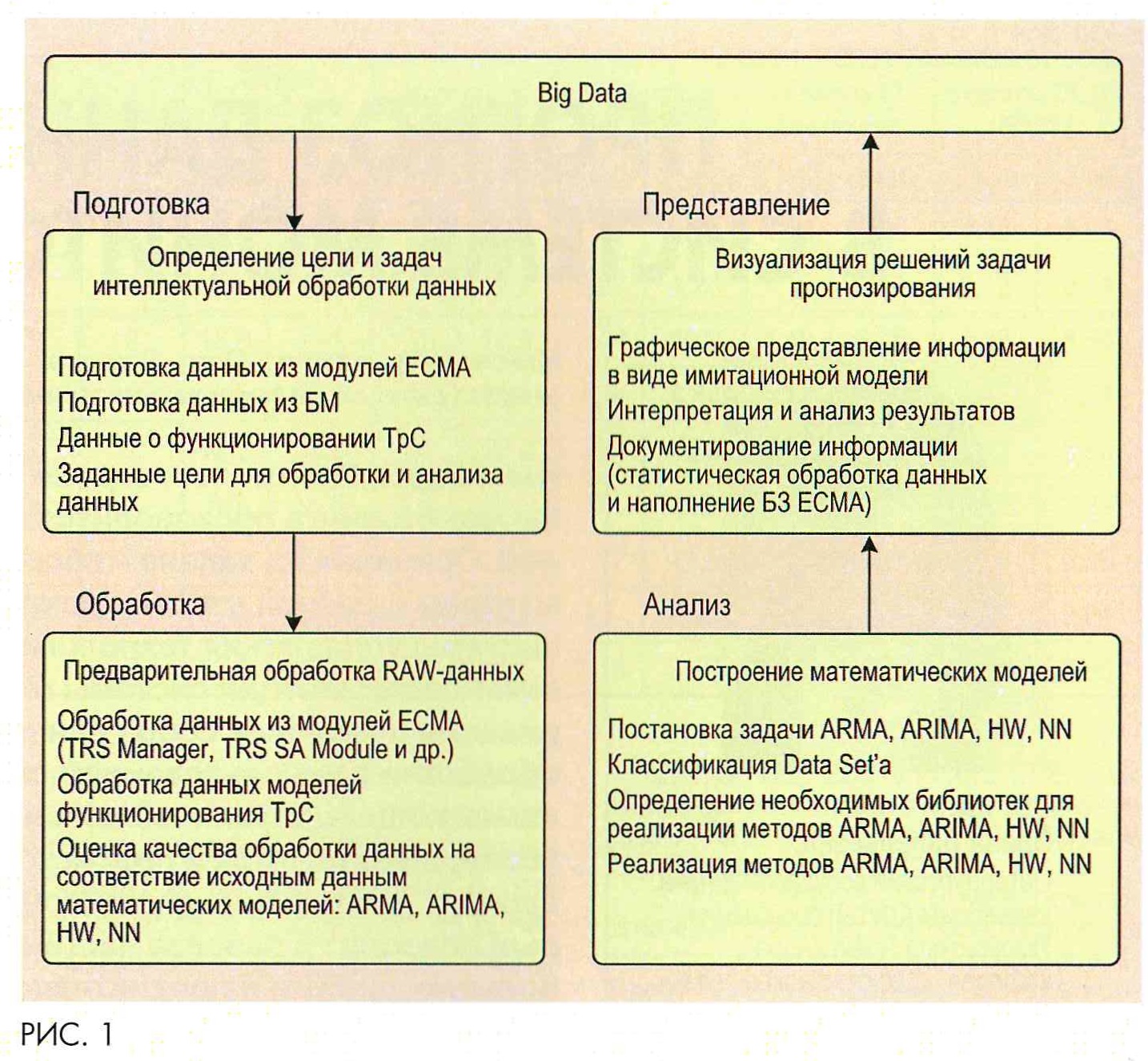
Этапы управления данными с учетом их структурирования на примере Big Data представлены на рис. 1. Датчики, установленные на объектах инфраструктуры, собирают сведения об эксплуатационных параметрах сети и передают в центральный узел с помощью надежной сети передачи. Процедуру сбора отличает наличие значительного количества данных - их становится много больше в связи с ростом эксплуатационных параметров, вводимых новых классификаторов параметров, а также параметров, характеризующих множество влияющих факторов на тот или иной эксплуатационный показатель. Необходима тщательная обработка данных, включая фильтрацию, поиск аномалий и очистку, а также предварительный анализ. Благодаря этому будет удаляться нерелевантная и неточная информация, что повысит качество последующего анализа. Обработанные данные размещаются и хранятся в специализированных системах, таких как база или хранилище данных, архитектура которых требует адаптации к новым возможностям и процессам с данными [9]. Это в перспективе обеспечит непрерывный доступ к данным для дальнейшего их анализа и обработки.
При этом анализ служит наиболее важным этапом управления. Используя методы статистического анализа и глубокого обучения, специалисты выявляют закономерности, определяют факторы, влияющие на возникновение инцидентов, и составляют прогноз возможных будущих сбоев в работе. Результаты анализа представляются не только в виде набора данных (Data Set), но и в наглядной форме, что облегчает понимание и выявление взаимосвязей и тенденций. Современные инструменты визуализации дают возможность отображать данные на интерактивных картах, графиках и диаграммах, что предусмотрено в новой системе ОУТ СС.
В действующей системе управления реализуются такие функции: сбор (не учитывает множество альтернативных источников данных, таких как Big Data), обработка (подчиняется требованиям подсистемы диагностики и мониторинга, не учитывает целевые функции для прогноза данных), хранение (выполняется за пределами служебного пользования, но не учитывается структура кластеров для хранения классификаторов). Также осуществляются функции набора данных, которые потребуются для обучения в некоторых моделях, анализ и визуализация (не учитывается формирование многовариантных прогнозов и их визуализация по целевым критериям, например, изменение оперативности и надежности при том или ином прогнозе, ключевой ресурс в выбранном срезе данных).
Можно использовать различные математические аппараты
для анализа, визуализации и наглядного представления методов обработки данных с прогнозированием. Некоторые из этих методов включают авторегрессию со скользящим окном (ARMA), авторегрессию со скользящим окном и обучением модели (ARIMA), экспоненциальное сглаживание (модель Хольта-Винтерса, HW) и регрессию (модель Ridge Regression, RR) [10-12].
На языке программирования Python был разработан код для каждого метода и получены графики с прогнозом. Все этапы управления данными (см. рис. 1) включены в программный код, математические модели основаны на наборе исходных данных Data Set с информацией об инцидентах в сети связи.
Данные были отфильтрованы по критерию инцидентов эксплуатационного характера по вине персонала и разбиты по месяцам, а для более точного и наглядного изображения прогноза использовались методы заполнения пропущенных значений, такие как заполнение средним и модой. На практике в реальных данных часто встречаются пропуски, аналитическая и математическая обработка которых транслирует накапливание таких ошибок в общем ряду новых уникальных данных. В случае текущего набора данных причиной пропущенных позиций являются ошибки ввода данных. В зависимости от их характера предлагается заполнять пропущенные позиции средним значением случайной величины, полученным при бесконечном числе испытаний, или модой (мода образует пик на графике функции распределения). Выбор среднего значения осуществлялся для тех статистически случайных наборов, вероятность и частота которых не соответствовали моде, т.е. пиковому положению выборки, а отклонение случайной величины от моды делало выборку наименее вероятной. Существует еще метод заполнения пропущенных позиций медианой. В этом исследовании он не использовался, поскольку положение медианы предусматривает работу с упорядочиваемыми данными, значения которых могут быть ранжированы [11].
Фильтрация и классификация данных выполнена с помощью внешних библиотек Python. При этом учитывались следующие факторы: период повтора события и его интенсивность. В модели Хольта-Винтерса отражено математическое выражение фактора события, например, появление отказа в один и тот же день каждого месяца/года при одинаковых интенсивностях исхода. В остальных моделях фактор так называемой сезонности не учитывался на этапе прогноза, но входил в модель метрики при интерпретации результатов.
ИНТЕРПРЕТАЦИЯ РЕЗУЛЬТАТОВ АНАЛИЗА ДАННЫХ ИССЛЕДУЕМОГО DATA SET
■ Для сравнения результатов моделирования прогнозных данных использовался метод метрики. Понятие «метрики» в контексте анализа данных и машинного обучения обозначает инструменты или методы, которые применяются для количественной оценки качества моделей, алгоритмов или прогнозов. Метрики помогают измерять, насколько хорошо модель или алгоритм решает конкретную задачу и какие улучшения могут быть сделаны.
Для регрессионных моделей, которые предсказывают непрерывные значения, и авторегрессионных моделей, которые используют предыдущие значения временного ряда для прогнозирования будущих значений, часто оперируют такими метриками, как среднеквадратическая ошибка, средняя абсолютная ошибка в процентах, коэффициент детерминации.
В результате изучения данных метрик и проведения анализа [13] для регрессионных и авторегрессионных моделей была выбрана метрика «среднеквадратическая ошибка (MSE)». Причем, чем ниже значение MSE, тем модель способна создавать более точный прогноз.
Итоговый прогноз в виде графиков, составленный по результатам реализации комплексной модели на основе перечисленных методов, представлен на рис. 2. Анализ полученных графиков позволяет оценить точность и характер прогнозов различных моделей временных рядов и машинного обучения на основе полученных данных о количестве инцидентов в сети связи.
Наибольшую точность функций прогноза моделей авторегрессии обеспечивает метод скользящего окна. Ширина скользящего окна показывает число наблюдений Data Set, на основе которых строится функция прогноза и считаются параметры для всех остальных моделей. Выбирается это значение исходя из срока прогнозирования.
Для нашего случая данные, полученные с помощью скользящего окна шириной 7, показывают более плавный тренд, который помогает выявить основные тенденции и сгладить краткосрочные колебания. Эта линия дает представление о базовом уровне инцидентов за рассматриваемый период.
Среднеквадратичная ошибка MSE вычисляется для всех моделей на основе последних 10 наблюдений. Меньшее значение MSE указывает на лучшую точность модели в прогнозировании. Отдельно выводится информация о модели с наименьшим значением MSE, что позволяет определить, какая из них выдает более точный прогноз на текущем наборе данных.
Прогноз авторегрессионной модели (AR) основывается на предыдущих данных и использует авторегрессионный компонент для предсказания будущих значений. Полученный результат засвидетельствовал отсутствие корреляции будущих и прошлых данных, а метрика ошибки показала один из лучших результатов, что говорит о достаточно высокой точности прогноза.
Модель ARIMA комбинирует авторегрессию, интеграцию (для устранения нестационарности) и скользящее среднее значение (функция среднего значения строит сглаженные точки главного ряда наблюдений). Она как раз подходит для текущих данных с трендами и случайными колебаниями. Прогнозы модели ARIMA учитывают эти компоненты, что дает более точный прогноз для временных рядов со сложными паттернами. Результат данной модели оказался наиболее точным по измеренной метрике, а характер прогноза наиболее адекватным по сравнению с моделями Ridge Regression и Хольта Винтерса, которые показали сильную чувствительность к конфигурациям исходного Data Set.
Модель Ridge Regression использует линейную регрессию с регуляризацией, предсказывая будущие значения на основе предыдущих. Прогнозы этой модели зависят от выбранной ширины окна наблюдений (в данном случае 8, поскольку меньшее значение привело бы к «пропуску» тех аномальных значений, сезонность или факторы которых установлены при конфигурировании Data Set; а большее значение -возможно только при увеличении размера прогноза, минимум на 20 месяцев). Регуляризация помогает избежать переобучения и улучшить устойчивость модели к шуму в передаче данных. Данный прогноз получил самый большой результат метрики и поэтому является самым ненадежным. Однако для конечных предложений использования данного метода нужно иметь оптимальное соотношение параметров или факторов сезонности, набор наблюдений и другие конфигурации модели, а, возможно, и моделирование для других источников данных.
Прогнозы модели Хольта-Винтерса показывают как сезонные колебания, так и общий тренд в данных. Эта модель хорошо подходит при наличии явных сезонных паттернов. Причем, если такие паттерны есть, модель должна их уловить. Однако, если данные не имеют выраженной сезонности, точность этой модели может быть ограниченной. Все это и было заложено в Data Set - отсутствие регулярных внешних факторов (сезонность паттернов не прослеживалась), а причинность трендов не была исследована полностью.
Заключение о том, что модель ARIMA является самой точной,
нельзя считать основным, так как в текущем срезе данных выбранные оцениваемые параметры (метрики, сезонности паттернов, неизученность аномалий и их корреляция с последующими событиями, количество этапов обучения моделей, ширина скользящего окна и окна наблюдения, и, наконец, размерность исходного Data Set) дополнительно не исследовались. Все это представляет собой предмет последующего изучения.
Полученный результат, представленный на рис. 2, свидетельствует о работоспособности рассмотренных моделей анализа данных, актуальность наиболее простых (математических) методов относительно обучаемых моделей, необходимость в масштабировании этапа метрической оценки прогнозов и добавления «мягких» вычислений для интерпретации общих результатов.
В заключение можно подвести итог: интеллектуальная обработка данных - это процесс анализа, интерпретации и вывода информации из больших объемов данных с использованием методов искусственного интеллекта, машинного обучения и других технологий. Она нужна для выявления закономерностей, трендов и паттернов в данных, что позволяет делать более точные прогнозы, принимать более обоснованные решения и оптимизировать бизнес-процессы.
Поскольку обработка и анализ данных - взаимодополняющие этапы работы с большими объемами данных, а телекоммуникации ОАО «РЖД» требуют новых вызовов в обслуживании и эксплуатации данных, полученный в исследовании результат может служить направлением развития систем мониторинга, диагностики и управления данными в целом.
Точки роста предлагаемой модернизации лежат в плоскости еще более детального исследования данных, которыми располагает телекоммуникационный сектор компании. При этом формирование Data Set в непрерывном и автоматизированном режиме, а также цифровой площадки для непрерывного обучения моделей (перспективных модулей)требует взаимодействия специалистов разных подразделений, а также наличия мощных вычислительных ресурсов.
СПИСОК источников
1. Стратегия цифровой трансформации РЖД/ZTADVISER. Государство. Бизнес. Технологии: портал. 2023. 07 авг. URL: https://www.tadviser.ru/ index.рбр/Статья:Стратегия_цифро-вой_трансформации_РЖД.
2. Азерников Д.В. Создание цифрового двойника инфраструктуры связи на Российском стеке // Автоматика, связь, информатика. 2022. №12. С. 9-13.
3. Наука о данных Data Science И TADVISER. Государство. Бизнес. Технологии: портал. 2023. 01 дек. URL: https://www.tadviser.ru/ index.php/Ста-тья: Наука_о_данных_(Оа1а_5с1епсе).
4. Data science - наука о данных, как стать data scientist с нуля // Future2Day.ru : сайт. 2019.25 окт. URL: https://future2day.ru/data-science/7ysclid =lefyv1nfni774037047.
5. Ульянова Е.В. Big Data: технология, принципы и архитектура//Журнал Суда по интеллектуальным правам. 2020. № 4 (30). С. 32-41
6. Логин Э.В. Методика формирования системы управления транспортной сетью связи ОАО «РЖД» : дис. ... канд. техн, наук : 05.12.13 / Место защиты: Гос. университет морского и речного флота им. С.О. Макарова. СПб, 2018. 144 с.
7. Канаев А.К., Логин Э.В., Гришанов И.С. Комплексный алгоритм процессов контроля и управления телекоммуникационной сетью Carrier Ethernet с применением механизмов ОАМ // Известия Петербургского университета путей сообщения. 2022. Т. 19, №2. С. 266-275.
8. Канаев А.К., Логин Э.В., Соколова А.В. Совершенствование системы мониторинга сети связи на основе Data Science // Автоматика, связь, информатика. 2023. № 5. С. 12-15.
9. Канаев А.К., Логин Э.В., Пудовкина К. А. Информационная модель перспективной базы данных в системе управления телекоммуникационной сетью Carrier Ethernet // Известия петербургского университета путей сообщения. 2022. Т. 19. Na 3. С. 266-275.
10. Соболев К.В. Автоматический поиск аномалий во временных рядах : магистерская диссертация : 03.04.01 / Место защиты: Московский физико-технический институт. М., 2018. 53 с.
11. Обработка пропусков в данных // www.loginom.ru: сайт. URL: https:// loginom.ru/blog/missing
12. Салихов М. Логит-регрессия в R // RPubs.com: сайт. URL: https://rpubs. com/smarcel/logit.
13. Метрики качества линейных регрессионных моделей // Loginom : сайт сайт. 2022. 12 дек. URL: https:// loginom.ru/blog/quality-metrics.



